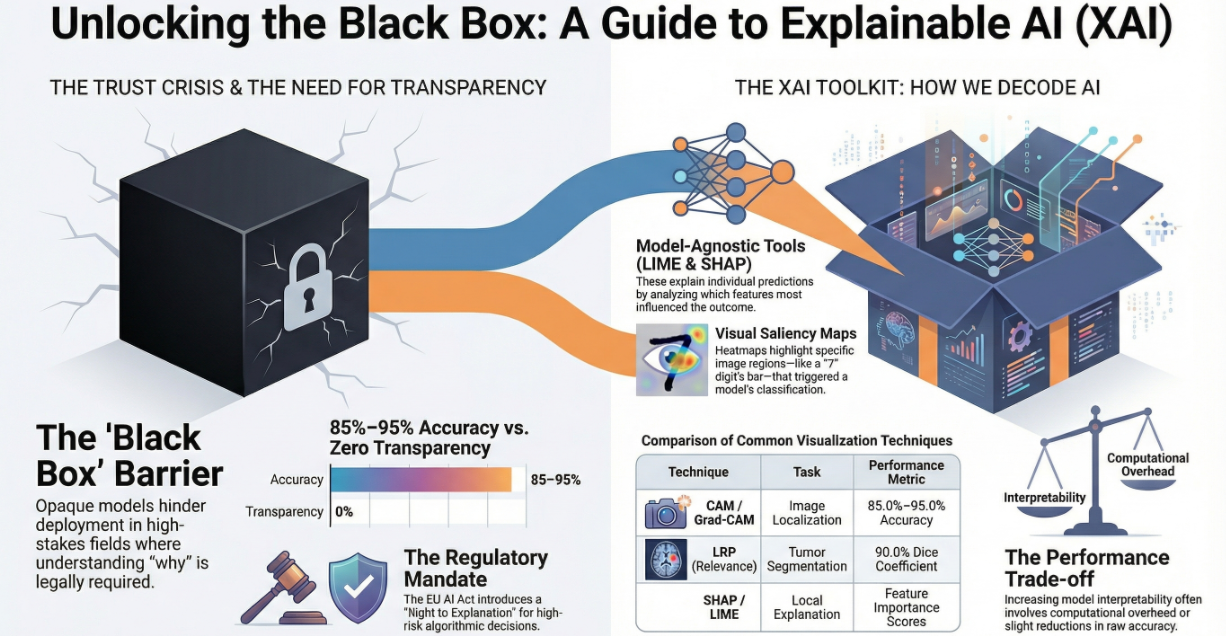
In recent years, artificial intelligence has advanced at a staggering pace. Sophisticated models now influence life-altering decisions, ranging from medical diagnoses to the approval of financial credit. However, as these systems have grown in complexity, they have also become increasingly opaque. This has precipitated a crisis known as the "black box problem"; a scenario where the internal logic of high-dimensional models is so complex that even their developers cannot fully articulate how a specific conclusion was reached. For sectors like healthcare and finance, where accountability is a non-negotiable requirement, this lack of transparency is no longer tenable.
Distinguishing Interpretability from Explainability
To navigate this field, it is essential to clarify two terms often used interchangeably: interpretability and explainability.
The Shifting Regulatory Landscape
Explainable AI has moved from a technical preference to a strict legal necessity. The European Union’s General Data Protection Regulation (GDPR) famously introduced a "right to explanation" for automated decisions. More recently, the EU AI Act has established a rigorous framework for "high-risk" AI systems. These systems must now be designed for traceability and transparency, providing deployers with clear instructions that detail their capabilities, limitations, and levels of accuracy.
Methods for Unlocking the Box
Researchers have developed several strategies to bridge the transparency gap:
The Power of "Human-in-the-Loop" (HITL)
The future of AI lies not in total automation, but in a synergistic partnership between human expertise and machine scale. A Human-in-the-Loop framework integrates human judgment into the AI’s validation process. Recent studies in financial regulatory risk assessment have shown that HITL systems can increase fraud detection accuracy by 15% and reduce decision-making time for compliance officers by 40%. By allowing experts to review and override AI "reason codes," organisations can foster the trust and accountability required in highly regulated environments.
Ethical Considerations and the "Glass Box" Movement
Ensuring AI can explain itself is an ethical imperative. It is the primary defence against algorithmic bias. When a system can articulate its reasoning, developers can identify if it is relying on "spurious correlations" such as a medical model focusing on a ruler in a photo rather than the skin lesion itself.
Prominent researchers now advocate for "glass box" models; systems built to be interpretable from the ground up, especially for high-stakes decisions in criminal justice and healthcare. The argument is simple: if a transparent model can achieve the same accuracy as a black box, the black box should not be used.
The Generative AI Challenge
As we enter the age of Large Language Models (LLMs) like GPT, Claude and Gemini, the XAI challenge remains an open problem. Standard tools like LIME and SHAP are often inadequate for these recursive, massive architectures. Current research is shifting toward mechanistic interpretability, attempting to reverse-engineer these models neuron by neuron to ensure they remain safe, fair, and aligned with human values.
Sources include:
Intrinsically Interpretable explainable AI, XAI World Conference
Is Attention Interpretable in Transformer-Based Large Language Models?, Hugging Face
Humans in the Loop: The Design of Interactive AI Systems, Stanford HAI